Bash 命令
由于核心在内存中是受保护的区块,因此我们必须要通过“ Shell ”将我们输入的指令与Kernel 沟通,好让 Kernel 可以控制硬件来正确无误的工作。
学习shell的主要原因及注意项:
- 命令行的 shell 在各大 distribution 都一样;
- 远端管理时命令行速度较快;
- shell 是管理 Linux 系统非常重要的一环,因为 Linux 内很多控制都是以 shell撰写的;
- 系统合法的 shell 均写在 /etc/shells 文件中;
- 使用者默认登陆取得的 shell 记录于 /etc/passwd 的最后一个字段;
- bash 的功能主要有:命令编修能力;命令与文件补全功能;命令别名设置功能;工作控制、前景背景控制;程序化脚本;万用字符;
- type 可以用来找到执行指令为何种类型,亦可用于与 which 相同的功能。
Shell 变量
变量就是以一组文字或符号等,来取代一些设置或者是一串保留的数据。变量主要有环境变量与自订变量,或称为全域变量与区域变量。
变量取用与设置
变量的取用:echo,如 echo $var 或 echo ${var}。
变量的设置:
- 变量与变量内容以一个等号“=”来链接,如 myname=Hoopan
- 等号两边不能直接接空白字符,如错误示例 myname = Hoopan 或 myname=Hoopan Zhou
- 变量名称只能是英文字母与数字,但是开头字符不能是数字,如错误示例 2myname=Hoopan
- 变量内容若有空白字符可使用双引号“"”或单引号“’”将变量内容结合起来
- 双引号内的特殊字符如 $ 等,可以保有原本的特性,如下所示: “var="lang is $LANG"”则“echo $var”可得“lang is zh_TW.UTF-8”
- 单引号内的特殊字符则仅为一般字符 (纯文本),如下所示: “var=’lang is $LANG’”则“echo $var”可得“lang is $LANG”
- 用转义字符“\”将特俗符号(如[Enter],$,\,空白字符等)变为一般字符,如myname=Hoopan\ Zhou
- 在命令中需要获取其他额外指令提供的信息,可以使用反单引号 ` 或 $(指令),如version=$(uname -r)
- 自定义变量变为环境变量,以便在其他子程序执行,使用 export,如 export myname
- 通常大写字符为系统默认变量,自行设置变量可以使用小写字符
- 取消变量的方法为使用 unset,如 unset myname
# 取用变量
echo $HOME
echo ${HOME}
# 定义变量
myname=Hoopan
myname=Hoopan\ Zhou
myname='Hoopan Zhou'
hello="Hi, I am ${myname}"
# 额外指令
version=$(uname -r)
echo $version
# 进入核心模块目录
cd /lib/modules/`uname -r`/kernel
cd /lib/modules/$(uname -r)/kernel
# 转为环境变量
export myname
bash
echo $myname
exit
# 取消变量
unset myname
环境变量与自订变量
相关命令:
- env :查看所有环境变量
- set :查看所有变量,含环境变量和自订变量
- export :自订变量转为环境变量
常见变量:
- HOME :当前用户的主文件夹,cd直接返回的目录
- SHELL :目前使用的shell程序
- HISTSIZE :历史命令条数
- PATH :可执行文件搜寻的路径
- LANG :语言
- PS1 :提示字符,终端每行前缀的提示内容,可以个性化定制,如增加git分支等
其他功能
- read :读取键盘输入的变量,选项 -p 提示语,-t 等待秒数,参数接变量名
- declare :声明变量类型,选项与参数如下
- -a :定义变量为数组(array)类型
- -i :定义变量为整数(integer)类型
- -x :将变量转为环境变量,类似export
- -r :变量设为只读 readonly 类型,不能被修改或unset
- -p :列出变量声明的类型
- 选项参数全部留空,输出全部变量,类似set
注意:
- 变量类型默认为“字串”,所以若不指定变量类型,则 1+2 为一个“字串”而不是“计算式”;
- bash 环境中的数值运算,默认最多仅能到达整数形态,所以 1/3 结果是 0。
# 读取键盘输入变量
read -p 'Please input your name: ' myname
echo $myname
# 定义整数
declare -i sum=1+2
# 输出结果3,若声明会原样输出1+2字符串
echo $sum
# 自订变量转环境变量
declare -x sum
# 再转回自订变量
declare +x sum
# 定义数组,使用中括号[]
var[1]=aaa
var[2]=bbb
echo ${var[1]}
环境配置文件
上一节谈到的命令别名、自订变量等,在登出bash后会失效。如果想下次登录bash时保留设置的内容,需要将这些设置写入到配置文件。
login 与 non-login shell
- login shell :取得 bash 时需要完整的登陆流程的,就称为 login shell。指输入账密登录的shell。获取环境配置文件如下
- /etc/profile :系统整体的设置,一般不要修改
- ~/.bash_profile 或 ~/.bash_login 或 ~/.profile:属于使用者个人设置,要修改的设置都写在这里
- non-login shell :需要账密登录,比如其他软件启动的bash,或在原bash环境再次下达bash命令的子程序,都是non-login shell
- ~/.bashrc :non-login shell读取此配置文件
- source :读入环境配置文件,也可用 .,这样就无须重新登录shell了
- ~/.bash_logout :登出bash后,系统会做完哪些动作才离开
# 读入环境配置文件,一般修改后使用则立即生效
source ~/.bashrc
. ~/.bashrc
命令别名
- alias :后接{“别名”=’指令 选项…’ },定义规则与变量定义规则类似,如 alias lm=’ls -al | more’
- unalias :取消别名
- history :历史命令,选项 n 最近几行命令,-c 清除历史命令,历史命令存在 ~/.bash_history 文件
# 命令别名
alias lm='ls -al | more'
# 执行别名命令
lm
# 取消别名
unalias lm
# 历史命令,最近10条
history 10
# 执行第几笔命令 !number
!66
#执行最近开头为某字符串的命令 !command
!hist
# 执行上一个命令,类似↑键Enter
!!
Bash 组合键与特殊符号
组合键:
- Ctrl + C :终止目前的命令
- Ctrl + D :输入结束 (EOF)
- Ctrl + M :就是 Enter
- Ctrl + S :暂停屏幕的输出
- Ctrl + Q :恢复屏幕的输出
- Ctrl + U :在提示字符下,将整列命令删除
- Ctrl + Z :“暂停”目前的命令
万用字符:
- * :代表“ 0 个到无穷多个”任意字符
- ? :代表“一定有一个”任意字符
- [] :代表“一定有一个在括号内”的字符,如[abcd]会存在任何一个
- [-] :表示编码顺序内的所有符号,如[0-9]表示0到9
- [^] :反向选择,非括号内的字符
特殊符号:
- # :注解符号:这个最常被使用在 script 当中,视为说明!在后的数据均不执行
- \ :转义字符
- | :管线(pipe)
- ; :联系指令下达分隔符号
- ~ :当前家目录
- $ :变量前置符号
- & :工作控制,将指令变为后台运行
- ! :逻辑非
- / :目录符号
- >,>> :数据流导出,分别是取代和累加
- <,<< :数据流导入
- ‘ :单引号
- " :双引号,有变量置换功能
- ` :先执行的指令,与$()功能一致
- () :在中间为子 shell 的起始与结束
- {} :在中间为命令区块的组合
# 列出cron开头的文件
ls -al /etc/cron*
# 列出文件名刚好是5个字母的
ll /etc/?????
# 列出含有数字的
ll /etc/*[0-9]*
数据流重导向
数据流重导向是指将某个指令执行后原本应该输出到屏幕的数据,传输到其他地方,如文件或设备。
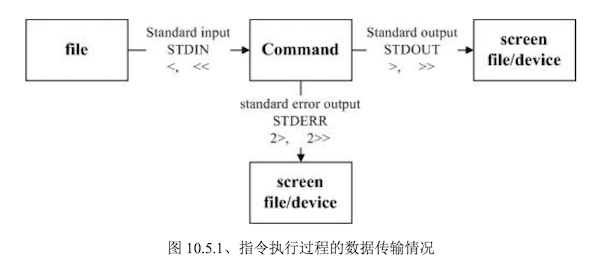
- 标准输出 standard output 简称 stdout :指令执行后所回传的正确信息。代码为 1,使用 > 或 >>
- 标准错误输出 standard error output 简称 stderr :指令执行失败后所回传的错误信息。代码为 2,使用 2> 或 2>>
- 标准输入 standard input 简称 stdin :标准输出的信息可以成为管道命令的标准输入信息。代码为 0,使用 < 或 <<
一般无论标准输出或标准错误输出,都会直接显示在屏幕上。但通过数据流重导向可以将这些信息分别输出到指定文件或设备。
/dev/null 垃圾桶黑洞设备
如果想让错误信息忽略掉不显示或存储,可以使用黑洞设备/dev/null。
输出重导向的作用主要是:
- 屏幕输出的信息很重要,而且我们需要将他存下来的时候;
- 背景执行中的程序,不希望他干扰屏幕正常的输出结果时;
- 一些系统的例行命令 (例如写在 /etc/crontab 中的文件) 的执行结果,希望他可以存下来时;
- 一些执行命令的可能已知错误讯息时,想以“ 2> /dev/null ”将他丢掉时;
- 错误讯息与正确讯息需要分别输出时。
命令执行的判断依据
- ; :cmd1 ; cmd2,不考虑指令相关性的连续指令下达
- && :cmd1 && cmd2,只有 cmd1 执行完毕且正确执行($?=0),才会开始执行 cmd2
- || :cmd1 || cmd2,只有 cmd1 执行完毕且为错误 ($?≠0),才会开始执行 cmd2
# 屏幕输出信息导出到文件
ll / > ~/rootfile
# 将stdout 与 stderr 存到不同文件
find /home -name .bashrc > list_right 2> list_error
# 利用黑洞丢弃错误信息
find /home -name .bashrc 2> /dev/null
# 将正确与错误信息导出同一个文件,使用 &> 或 2>&1
find /home -name .bashrc &> list
# cat创建一个文件,使用下面命令然后键盘输入信息,最后 ctrl+d结束
cat > catfile
# 利用stdin取代键盘输入以创建文件
cat > catfile < ~/.bashrc
# << 表示结束的输入字符,取代刚才的 ctrl+d
cat > catfile << "eof"
#> test
#> eof ##最后一行输入eof字符,就能结束了,不需要按 ctrl+d
# 多条命令执行,无关联性
sync; sync; shutdown -h now
# 第一条命令执行成功才执行第二条
ls /tmp/abc && touch /tmp/abc/hehe
# 第一条命令不成功才执行第二条
ls /tmp/abc || mkdir /tmp/abc
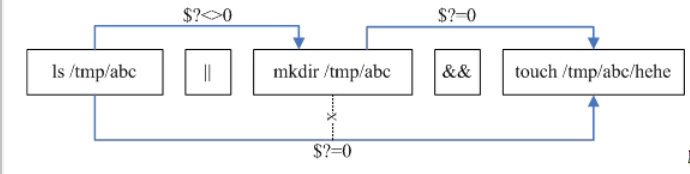
同时使用 && 和 ||,会有一些特别的效果,看下图及示例代码
ls /tmp/abc || mkdir /tmp/abc && touch /tmp/abc/hehe
管线命令 pipe
管线命令“|”需要注意:
- 管线命令仅会处理 standard output,对于 standard error output 会予以忽略;
- 管线命令必须要能够接受来自前一个指令的数据成为 standard input 继续处理才行。
相关管线命令:
- cut :切割字符串,选项 -d 后接分隔字符,-f 取第几个,-c 以字符为单位取出固定字符区间
- grep :查询某行是否存在关键字,若存在则取出整行数据。选项 -c 统计查到关键字的次数,-i 忽略大小写,-n 输出行号,-v 反向选择,–color=auto 关键字加颜色
- sort :排序。选项 -f 忽略大小写,-b 忽略最前面的空白符,-n 纯数字排序(默认文字),-r 反序,-u 相同数据仅出现一行,-t 分隔符号(默认 tab键),-k 以分隔的哪个字段排序
- uniq :排序后重复的数据仅列出一个显示。选项 -i 忽略大小写,-c 计数
- wc :统计行数、字数。选项 -l 仅列出行数,-w 仅列出字数(英文单词),-m 仅列出字符数
- tee :双向重导向,将数据流分到两个地方。选项 -a 数据追加到file
- tr :内容替换或删除。选项 -d 删除某个字符串(适合处理单个字符替换)
- split :split [-bl] file PREFIX 分区切割文件。选项 -b 分区大小 单位 b、k、m等,-l 以行数分区,PREFIX 代表前置字符 作为分区文件的前缀
- xargs :参数替换,对非管线命令很有用。选项 -0 特殊字符转一般字符,-e 后接字符串,当分析到此字符串时停止,-p 每次执行指令要询问,-n 后接数字 指令使用几个参数
- sed :对数据新增、删除、替换等操作。功能强大
- 选项与参数:
- -n :使用安静模式。列出sed处理的行
- -e :直接在命令行界面上进行 sed 的动作编辑
- -f :直接将 sed 的动作写在一个文件内, -f filename 则可以执行 filename 内的 sed 动作
- -r :sed 的动作支持的是延伸型正则表达式的语法。(默认是基础正则表达式语法)
- -i :直接修改读取的文件内容,而不是由屏幕输出。
- 动作说明: [n1[,n2]]function
- n1, n2 :不见得会存在,一般代表“选择进行动作的行数”,举例来说,如果我的动作是需要在 10 到 20 行之间进行的,则“ 10,20[动作行为] ”
- function 有下面这些咚咚:
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正则表达式!例如 1,20s/old/new/g 就是啦!
- 选项与参数:
# 以“:”分隔,取第多个分隔的字段
echo ${PATH} | cut -d ':' -f 3,5
# 搜索有root的行
last | grep 'root'
# 正序
cat /etc/passwd | sort
# 以:分隔及第三栏字段排序
cat /etc/passwd | sort -t ':' -k 3
# 去除重复数据
last | cut -d ' ' -f 1 | sort | uniq
# 统计内容字数
cat /etc/man_db.conf | wc
# tee 同时将数据流分送到文件与屏幕
last | tee last.list | cut -d ' ' -f1
# 将所有小写改为大写
last | tr '[a-z]' '[A-Z]'
# 将冒号删除
cat /etc/passwd | tr -d ':'
# 将文件以300k切分
split -b 300k /etc/services services
# 将切分的文件合成
cat services* >> servicesback
# 利用xargs让非管线命令id输出多个用户的信息
cut -d ':' -f 1 /etc/passwd | head -n 3 | xargs -n 1 id
# 减号 - 的用途:可以作为stdout 或 stdin。如下复制文件
tar -cvf - /home | tar -xvf - -C /tmp/homeback
# 将换行符替换为逗号
ls | tr '\n' ','
# 删除某个字符
head -1 /etc/passwd | tr -d ':'
# sed 相关命令
# 删除一些行
nl /etc/passwd | sed '2,5d'
# 从下面插入新增一行
nl /etc/passwd | sed 'test test'
# 将特定行替换为其他内容
nl /etc/passwd | sed '2,5c No 2-5 number'
# 取出特定行
nl /etc/passwd | sed -n '5,7p'
# 部分数据查找替换,sed除了整行处理外,还可以对行内数据查找替换
sed 's/要被取代的字串/新的字串/g'
# 获取本地IP,ifcofig后接网卡名
ifconfig ens33 | grep 'inet ' | sed 's/^.*inet //g' | sed 's/ *netmask.*//g'
# 除了当行处理,sed还能跨行处理,如替换换行符(这部分内容暂未搞懂,参考https://blog.csdn.net/u011729865/article/details/71773840)
ls | sed ":a;N;s/\n/','/g;$!ba"
Shell 脚本
shell script 是利用 shell 的功能所写的一个“程序 (program)”,这个程序是使用纯文本文件,将一些 shell 的语法与指令(含外部指令)写在里面, 搭配正则表达式、管线命令与数据流重导向等功能,以达到我们所想要的处理目的。
shell script 用在系统管理上面是很好的一项工具,但是用在处理大量数值运算上, 就不够好了,因为 Shell scripts 的速度较慢,且使用的 CPU 资源较多,造成主机资源的分配不良。
脚本编写
- 在 Shell script 的文件中,指令的执行是从上而下、从左而右的分析与执行;
- 指令、选项与参数间的多个空白都会被忽略掉;
- 空白行也将被忽略掉,并且 [tab] 按键所推开的空白同样视为空白键;
- 如果读取到一个 Enter 符号 (CR) ,就尝试开始执行该行(或该串)命令;
- 至于如果一行的内容太多,则可以使用“ [Enter] ”来延伸至下一行;
- “ # ”可做为注解!任何加在 # 后面的数据将全部被视为注解文字而被忽略!
命令执行:
- 直接指令下达:shell脚本需要有 rx 权限,可以使用绝对或相对路径
- 以bash程序执行:通过如“bash test.sh” 执行,此时脚本只需有 r 权限
- 利用 source 执行脚本:在父程序里执行脚本,以上命令是在子程序里执行。对自订变量等影响不同
简单的shell示例:
#!/bin/bash
# 可以增加一些脚本说明,如功能、版本、作者、创建日期等
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin
export PATH
echo -e "hello world! \a \n"
exit 0整个程序有几个部分组成,大致如下:
- 第一行 #!/bin/bash 在宣告这个 script 使用的 shell 名称
- 程序内容的说明:说明脚本功能、版本等
- 主要环境变量的宣告: 建议务必要将一些重要的环境变量设置好
- 主要程序部分
- 执行结果告知(定义返回值),如 exit 0 表示程序执行成功
默认变量
脚本命令执行时,后接一些参数,脚本会自动接收这些参数。对应变量如下:

除了 $0 到 $n 之外,脚本内还有一些特殊参数变量:
- $# :代表后接的参数“个数”,以上表为例这里显示为“ 4 ”;
- $@ :代表“ "$1" "$2" "$3" "$4" ”之意,每个变量是独立的(用双引号括起来);
- $* :代表“ "$1 $2 $3 $4" ”之意,与$@稍微不同
shift:会造成参数变量号码偏移。
逻辑判断
可以利用 test 指令或 [] 判断符号,进行逻辑判断。常用的判断标志如下:
- -e :该“文件名”是否存在
- -f :该“文件名”是否存在且为文件(file)
- -d :该“文件名”是否存在且为目录(directory)?(常用)
- -r :检查该文件名是否存在且具有“可读”的权限
- -w :检查该文件名是否存在且具有“可写”的权限
- -x :检查该文件名是否存在且具有“可执行”的权限
- -nt :(newer than)判断 file1 是否比 file2 新
- -ot :(older than)判断 file1 是否比 file2 旧
- -eq :两数值相等 (equal)
- -ne :两数值不等 (not equal)
- -gt :n1 大于 n2 (greater than)
- -lt :n1 小于 n2 (less than)
- -ge :n1 大于等于 n2 (greater than or equal)
- -le :n1 小于等于 n2 (less than or equal)
- test -z string :判定字串是否为 0 ?若 string 为空字串,则为 true
- test -n string :判定字串是否非为 0 ?若 string 为空字串,则为false。 -n 亦可省略
- test str1 == str2 :判定 str1 是否等于 str2 ,若相等,则回传 true
- test str1 != str2 :判定 str1 是否不等于 str2 ,若相等,则回传 false
- -a :(and)两状况同时成立!例如 test -r file -a -x file
- -o :(or)两状况任何一个成立!例如 test -r file -o -x file
- ! :反相状态,如 test ! -x file ,当 file 不具有 x 时,回传 true
# 判断文件是否存在
test -e /hoopan && echo "exist" || echo "Not exist"
# []判断
# 注意:中括号用处较多,shell判断式的中括号两端必须有空白字符分隔!
[ -z "${HOME}" ] ; echo $?
[ "${yn}" == "Y" -o "${yn}" == "y" ] && echo "OK, continue" && exit 0
条件判断
利用 if … then
# 单层条件判断
if [ 条件判断式 ]; then
当条件判断式成立时,可以进行的指令工作内容;
fi
# 多重条件判断 if else
if [ 条件判断式 ]; then
当条件判断式成立时,可以进行的指令工作内容;
else
当条件判断式不成立时,可以进行的指令工作内容;
fi
# 多条件判断 if elif else
if [ 条件判断式一 ]; then
当条件判断式一成立时,可以进行的指令工作内容;
elif [ 条件判断式二 ]; then
当条件判断式二成立时,可以进行的指令工作内容;
else
当条件判断式一与二均不成立时,可以进行的指令工作内容;
fi
多个条件判断
- && :表示 and
- || :表示 or
一个中括号的判断可以拆解成多个中括号:
[ "${yn}" == "Y" -o "${yn}" == "y" ] 等价于 [ "${yn}" == "Y" ] || [ "${yn}" == "y" ]
利用 case … esac
case $变量名称 in #==关键字为 case ,还有变量前有钱字号
"第一个变量内容") #==每个变量内容建议用双引号括起来,关键字则为小括号 )
程序段
;; #==每个类别结尾使用两个连续的分号来处理!
"第二个变量内容")
程序段
;;
*) #==最后一个变量内容都会用 * 来代表所有其他值
不包含第一个变量内容与第二个变量内容的其他程序执行段
exit 1
;;
esac #== case反过来写,表示结束# 条件判断 if
read -p "Please input (Y/N): " yn
if [ "${yn}" == "Y" ] || [ "${yn}" == "y" ]; then
echo "OK, continue"
elif [ "${yn}" == "N" ] || [ "${yn}" == "n" ]; then
echo "Oh, interrupt!"
else
echo "I don't know what your choice is"
fi
# 条件判断 case
case ${1} in
"one")
echo "Your choice is ONE"
;;
"two")
echo "Your choice is TWO"
;;
"three")
echo "Your choice is THREE"
;;
*)
echo "Usage ${0} {one|two|three}"
;;
esac
自定义函数
函数 function 语法:
function fname() {
程序段
}- 注意:因为 shell script 的执行方式是由上而下,由左而右, 因此 function 一定要写在程序的最前面。(与其他语言不同)
函数传参
与shell脚本类似,$0 表示函数名称,$1 … $n 表示函数名后接的参数
# 自定义函数
function printit(){
echo -n "Your choice is " # 加上 -n 可以不断行继续在同一行显示
}
echo "This program will print your selection !"
case ${1} in
"one")
**printit**; echo ${1} | tr 'a-z' 'A-Z' # 将参数做大小写转换!
;;
"two")
**printit**; echo ${1} | tr 'a-z' 'A-Z'
;;
*)
echo "Usage ${0}"
;;
esac
# 自定义函数传参
function printit(){
echo "Your choice is ${1}" # 这个 $1 必须要参考下面指令的下达
}
echo "This program will print your selection !"
case ${1} in
"one")
**printit 1** # 请注意, printit 指令后面还有接参数!
;;
"two")
**printit 2**
;;
*)
echo "Usage ${0}"
;;
esac
循环
while do done
当 condition 条件成立时,就进行循环,直到 condition 的条件不成立才停止。
while [ condition ] #==中括号内的状态就是判断式
do #==do 是循环的开始!
程序段落
done #==done 是循环的结束until do done
当 condition 条件成立时,就终止循环, 否则就持续进行循环的程序段。
until [ condition ]
do
程序段落
done# while 循环
while [ "${yn}" != "yes" -a "${yn}" != "YES" ]
do
read -p "Please input yes/YES to stop this program: " yn
done
echo "OK! you input the correct answer."
# until 循环
until [ "${yn}" == "yes" -o "${yn}" == "YES" ]
do
read -p "Please input yes/YES to stop this program: " yn
done
# 累加1到100
s=0 # 这是加总的数值变量
i=0 # 这是累计的数值,亦即是 1, 2, 3....
while [ "${i}" != "100" ]
do
i=$(($i+1)) # 每次 i 都会增加 1
s=$(($s+$i)) # 每次都会加总一次!
done
echo "The result of '1+2+3+...+100' is $s"
for…do…done
相对于 while, until 的循环方式是必须要“符合某个条件”的状态, for 这种语法,则是“ 已经知道要进行几次循环”的状态
有两种语法:
# 语法1
for var in con1 con2 con3 ... #第1次循环$var为con1,第2次循环$var为con2...
do
程序段
done
# 语法2
for (( 初始值; 限制值; 执行步阶 ))
do
程序段
done
示例:
# for in 循环
for animal in dog cat elephant
do
echo "There are ${animal}s.... "
done
# for 数值循环
read -p "Please input a number, I will count for 1+2+...+your_input: " nu
s=0
for (( i=1; i<=${nu}; i=i+1 ))
do
s=$((${s}+${i}))
done
echo "The result of '1+2+3+...+${nu}' is ${s}"
debug
编写完成一个脚本后,可以进行debug,以排查语法或执行是否存在问题。
- bash命令:选项 -n 检查是否有语法错误,-x 输出执行步骤
# 检查语法
bash -n sum.sh
# 输出执行步骤
bash -x sum.sh
正则表达式
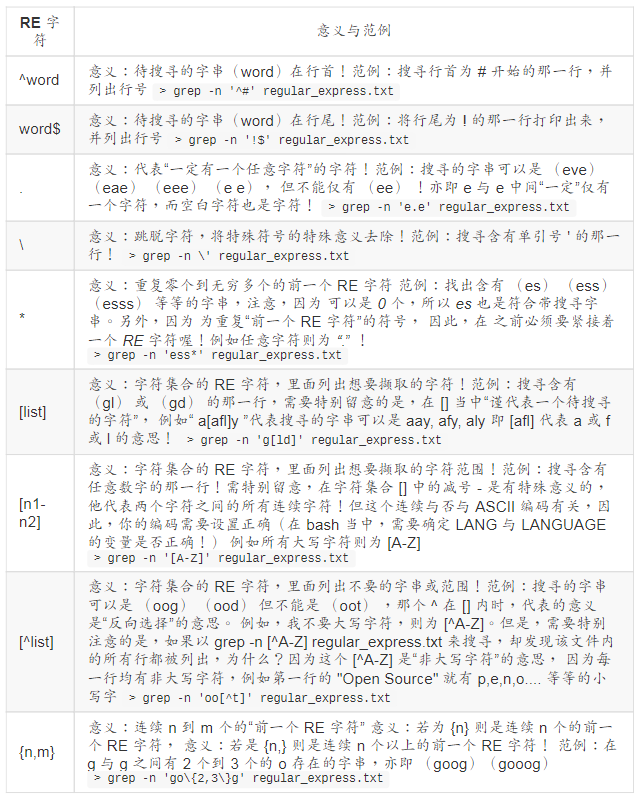
基础正则表达式
延伸正则表达式

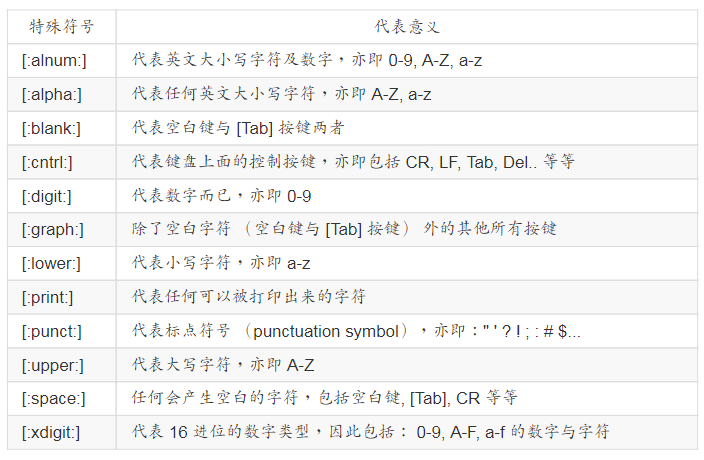
特殊符号
# grep使用基础正则
grep -v '^$' regular_express.txt | grep -v '^#'
# egrep使用延伸正则
egrep -v '^$|^#' regular_express.txt
